You can view refer to my GitHub repo containing this project here.
As part of a course on leveraging Generative AI with LLMs, we were given an assignment with a fairly simple, yet highly open-ended premise: to fine tune an open-weight LLM on a clearly defined task such as classification or instruction-following.
The number one stumbling block to my progress was the limitless possibility of problems to tackle given the task. There were many datasets on sites like Kaggle or HuggingFace that could serve as candidates for the subject of my analysis. There were so many, in fact, that it took me nearly two weeks to settle on a dataset that was not only deep and rich enough for an LLM to learn from, but also well-maintained and documented for ease of use.
After much searching, I settled on the Glassdoor Job Reviews dataset by David Gauthier, found on Kaggle with a CC BY-SA 4.0 license.
The Dataset
It features 18 columns covering a number of categorical and numerical values like name of the firm, job title, overall rating, etc. But the main focus of this task is to predict whether the reviewer would recommend the job based on the pros and cons listed.
EDA
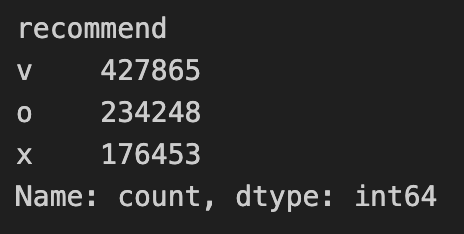
The dataset has over 838000 reviews, which is far too large for fine-tuning any model in a reasonable amount of time. This prompted the use of subsampling down to a sample size of 100000 reviews instead.
Of the target variable recommend, approximately 51% of
data comprised positive reviews, 28% neutral reviews, while the
remaining 21% were negative reviews.
resample from sklearn.utils was used to
ensure that the sampled dataset features approximately the same
proportions so that the data remains independent and identically
distributed. Preserving the class imbalance as-is will yield
interesting results later on.
I additionally chose a train-val-test split of 80/10/10.
Feature Engineering
Given my intended purpose of fine-tuning an LLM for classification,
the feature engineering for the predictor variables is relatively
simple, as there are only two text-based columns that I deemed useful
for predicting the sentiment of a review, namely pros and
cons. The remaining text-based columns like
job_title or location are best represented
by categories that would be better served by other classification
algorithms.
To create a single text input for the model to learn from, I opted
for an extremely simple concatenation of the pros and
cons columns.
df_sampled['pros_cons'] = "Pros: " + df_sampled['pros'].fillna('') + " Cons: " + df_sampled['cons'].fillna('')
Model
RoBERTa-base was selected as the model for this task. It was pretrained with Masked Language Modeling (MLM) which strengthens contextual understanding, which is crucial for potentially ambiguous or neutral pros and cons. Its masks change every epoch, helping to reduce overfitting. It was also trained on more data compared to BERT, beating the latter in various benchmarks like GLUE and SST-2 for sentiment analysis.
RoBERTa-large was also considered as higher capacity could potentially capture subtler patterns, but training time and memory requirements are significantly higher. Given the practical constraints on top of exploring five separate hyperparameter configurations, the incremental gain may not justify the extra time.
Metrics
Accuracy and F1-score were chosen as metrics to judge model performance as this is a simple classification task.
Results
Base Model
The base model, without any training or fine-tuning, produced a validation accuracy of 28% and a validation F1 score of 12.3%.
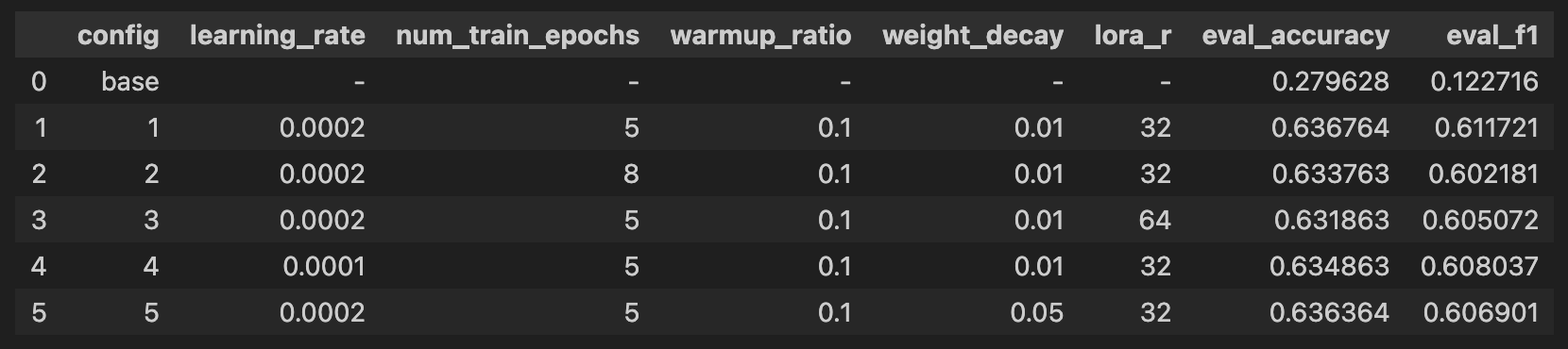
Hyperparameter Configurations
I tested five different configurations as per the table below:
| No. | Learning Rate | Epochs | Weight Decay | LoRA rank | LoRA alpha |
|---|---|---|---|---|---|
| 1 | 2e-4 | 5 | 0.01 | 32 | 64 |
| 2 | 2e-4 | 8 | 0.01 | 32 | 64 |
| 3 | 2e-4 | 5 | 0.01 | 64 | 128 |
| 4 | 1e-4 | 5 | 0.01 | 32 | 64 |
| 5 | 2e-4 | 5 | 0.05 | 32 | 64 |
The batch size and warmup ratio were kept the same across all five configurations, at 16 and 0.1 respectively.
Validation batch size was kept to 8.
Evaluation Metrics
The final validation F1 scores for each of the configurations is displayed below. The scores lie within close to 1% of each other, which suggests that this result is not so much an issue of the hyperparameter configurations themselves, rather the richness of the data (which, based on a concatenation of pros and cons, is not too sophisticated).
Confusion Matrix
| True \ Predicted | Positive | Neutral | Negative |
|---|---|---|---|
| Positive | 4277 | 498 | 327 |
| Neutral | 1682 | 722 | 390 |
| Negative | 522 | 209 | 1373 |
The majority of positive and negative reviews were correctly predicted, in spite of negative reviews being numerically inferior to the other two classes.
The comparatively poor performance in correctly predicting neutral reviews could come down to the following factors:
- The high number of predicted positives on true neutrals could come down to the dataset being dominated by positive-labeled reviews. Training on mostly positive reviews might have made the model more likely to conclude a review is positive if it’s potentially ambiguous (which I guess is true for humans too)
- The model struggles with ambiguity. The numerically scarce negative reviews still scored a higher accuracy (~65%) compared to neutral ones.
Conclusion and Next Steps
The use of a fine-tuned LLM serves as a worthy starting point in predicting sentiment based on textual reviews. However, the task could greatly benefit from running classification or regression on the several other categories present in the dataset, such as job title and location, or numerical values like ratings of compensation and benefits, work-life balance, and opinion on senior management.
Other machine learning architecture like multi-layer perceptrons could potentially excel at involving these variables as predictors, and could complement LLM fine-tuning as part of a pipeline to predict Glassdoor review sentiment with greater accuracy.